
Рассмотрение конструкций PIVOT и UNPIVOT
Текстовый материал
Язык T-SQL позволяет не просто выгружать данные, а строить целые отчеты с глубоким анализом, для этого предусмотрены специальные конструкции.
И одной из таких конструкций является PIVOT, который позволяет формировать так называемые «Сводные таблицы».
PIVOT
PIVOT – это оператор языка T-SQL, который поворачивает результирующий набор данных, преобразуя уникальные значения одного столбца в несколько столбцов.
Такой функционал, например, в Excel, называют «Транспонирование», в SQL такие запросы называют перекрестные запросы или запросы с использованием кросс табличных выражений.
Данные запросы используются для того, чтобы развернуть результирующий набор данных. Иными словами, значения в столбце, которые расположены в таблице по вертикали, мы можем выстроить по горизонтали, применяя при этом агрегацию и группировку данных, таким образом, происходит формирование некой сводной таблицы. Пользоваться отчетами, где данные представлены в таком виде, очень удобно, такие отчеты очень любит начальство, поэтому скорей всего отчеты со сводными таблицами Вы будете формировать.
Примечание! К данном уроку прикреплен SQL скрипт, который создает необходимые объекты для выполнения всех примеров на этом уровне курса.
--Обычная группировка
SELECT C.CategoryName, AVG(G.Price) AS AvgPrice
FROM Goods G
LEFT JOIN Categories C ON G.Category = C.CategoryId
GROUP BY C.CategoryName;
--Группировка с использованием PIVOT
SELECT 'Средняя цена' AS AvgPrice, [Комплектующие компьютера], [Мобильные устройства]
FROM (SELECT G.Price, C.CategoryName
FROM Goods G
LEFT JOIN Categories C ON G.Category = C.CategoryId) AS SourceTable
PIVOT (AVG(Price) FOR CategoryName IN ([Комплектующие компьютера],[Мобильные устройства])
) AS PivotTable;
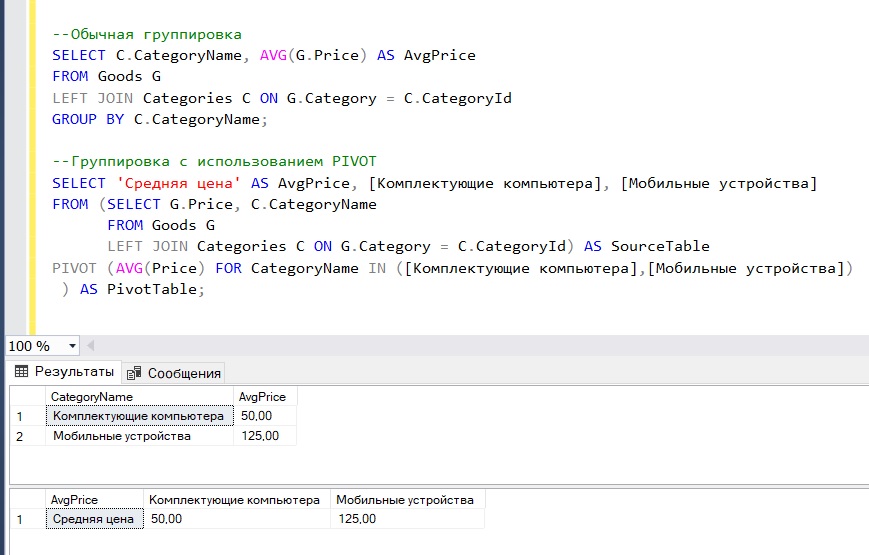
В этом примере мы сгруппируем данные в нашей тестовой таблице по категориям и узнаем среднюю цену товаров в каждой категории, при этом названия категорий мы расположим в столбцах. Также для сравнения сначала приведен пример с обычной группировкой, результат точно такой же, но названия категорий в одном столбце.
В данном случае:
- Псевдонимы из названий категорий – это значения в столбце CategoryName, которые мы заранее должны знать;
- SourceTable – это псевдоним выражения, в котором мы указываем исходный источник данных, например, вложенный запрос;
- PIVOT – вызов оператора PIVOT;
- AVG – это агрегатная функция, в которую мы передаем столбец для анализа, в нашем случае Price;
- FOR – с помощью данного ключевого слова мы указываем столбец, содержащий значения, которые будут выступать именами столбцов, в нашем случае CategoryName;
- IN – оператор, с помощью которого мы перечисляем значения столбца CategoryName;
- PivotTable – псевдоним сводной таблицы, его необходимо указывать обязательно.
UNPIVOT
Для того чтобы произвести обратное действие, т.е. преобразовать столбцы итогового набора данных в значения одного столбца, используется оператор UNPIVOT. Честно говоря, этот оператор требуется достаточно редко, в отличие от PIVOT, который в аналитике просто незаменим.
Для того чтобы посмотреть на работу оператора UNPIVOT, нам нужны данные, поэтому давайте создадим таблицу с подходящими для нас данными, при этом для закрепления материала, который мы прошли на прошлом уровне курса, создадим временную таблицу с помощью конструкции SELECT INTO.
--Создаём временную таблицу с помощью SELECT INTO
SELECT 'Город' AS TypeRec,
'Москва' AS Column1,
'Калуга' AS Column2,
'Тамбов' AS Column3
INTO #TestUnpivot;
--Смотрим, что получилось
SELECT * FROM #TestUnpivot;
--Применяем оператор UNPIVOT
SELECT TypeRec, ColumnName, CityName
FROM #TestUnpivot
UNPIVOT(CityName FOR ColumnName IN ([Column1],[Column2],[Column3])
)AS UnpivotTable;

Где,
- TestUnpivot – таблица источник, в нашем случае временная таблица;
- CityName – псевдоним столбца, который будет содержать значения наших столбцов;
- FOR – ключевое слово, с помощью которого мы указываем псевдоним для столбца, который будет содержать имена наших столбцов;
- ColumnName – псевдоним столбца, который будет содержать имена наших столбцов;
- IN – ключевое слово для указания имен столбцов.
Следует отметить то, что оператор UNPIVOT не восстанавливает данные, сгруппированные оператором PIVOT, он просто разворачивает итоговый набор данных.
Недостатком данных операторов является то, что у них очень специфический синтаксис, и они требуют некой ручной работы, т.е., например, выходные столбцы у PIVOT должны быть перечислены вручную. Однако T-SQL – это все-таки язык программирования, поэтому существует возможность реализовать так называемый динамический PIVOT, с помощью динамического T-SQL кода, а как его писать, Вы узнаете на следующих уроках этого курса.
Никогда ранее не сталкивалась с таким оператором, но сталкивалась с “аналогами” ))) Оператор проще понять ))) Лично я бы добавила синтаксис из официальной документации, мне так проще воспринимать конструкцию )
Ну и пошли вопросы )))
1. А если мне надо среднюю, а в следующей строке количество, а потом количество пустых и т.д. – как это формируется? Несколько таких конструкций PIVOT через UNION например?
2. Можно ли использовать при создании витрины?
Урок очень понравился, спасибо.